准备依赖
要开发 Flink CEP 应用程序,首先你得在项目的 pom.xml 中添加依赖。
1 | <dependency> |
这个依赖有两种,一个是 Java 版本的,一个是 Scala 版本,根据项目的开发语言自行选择。
Flink CEP 应用入门
准备好依赖后,我们开始第一个 Flink CEP 应用程序,这里我们只做一个简单的数据流匹配,当匹配成功后将匹配的两条数据打印出来。首先定义实体类 Event 如下:
1 | public class Event { |
然后构造读取 Socket 数据流将数据进行转换成 Event,代码如下:
1 | SingleOutputStreamOperator<Event> eventDataStream = env.socketTextStream("127.0.0.1", 9200) |
接着就是定义 CEP 中的匹配规则了,下面的规则表示第一个事件的 id 为 42,紧接着的第二个事件 id 要大于 10,满足这样的连续两个事件才会将这两条数据进行打印出来。
1 | Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where( |
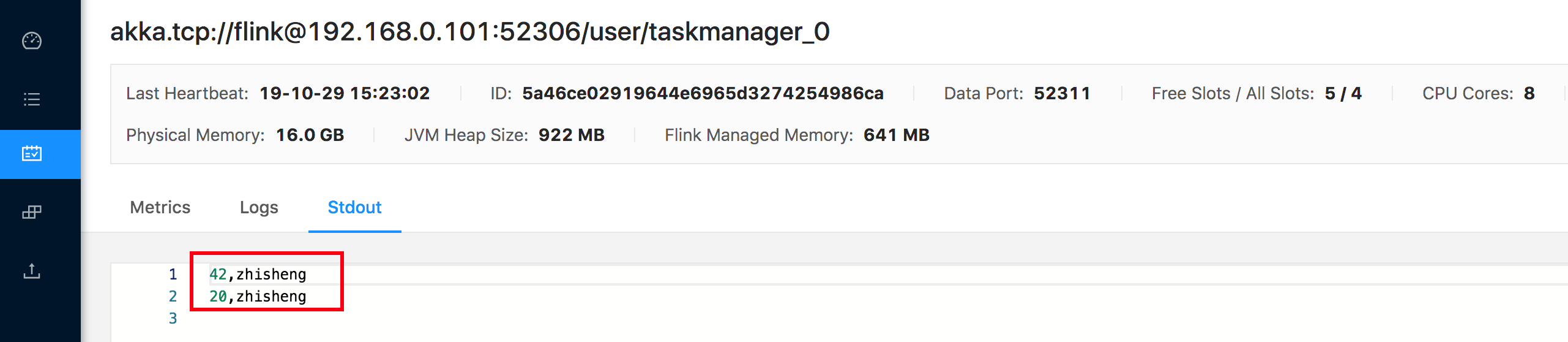
然后笔者在终端开启 Socket,输入的两条数据如下:
1 | 42,zhisheng |
作业打印出来的日志如下图:

整个作业 print 出来的结果如下图:
好了,一个完整的 Flink CEP 应用程序如上,相信你也能大概理解上面的代码,接着来详细的讲解一下 Flink CEP 中的 Pattern API。
Pattern API
你可以通过 Pattern API 去定义从流数据中匹配事件的 Pattern,每个复杂 Pattern 都是由多个简单的 Pattern 组成的,拿前面入门的应用来讲,它就是由 start 和 middle 两个简单的 Pattern 组成的,在其每个 Pattern 中都只是简单的处理了流数据。在处理的过程中需要标示该 Pattern 的名称,以便后续可以使用该名称来获取匹配到的数据,如 p.get("start").get(0) 它就可以获取到 Pattern 中匹配的第一个事件。接下来我们先来看下简单的 Pattern 。
单个 Pattern
数量
单个 Pattern 后追加的 Pattern 如果都是相同的,那如果要都重新再写一遍,换做任何人都会比较痛苦,所以就提供了 times(n) 来表示期望出现的次数,该 times() 方法还有很多写法,如下所示:
1 | //期望符合的事件出现 4 次 |
条件
可以通过 pattern.where()、pattern.or() 或 pattern.until() 方法指定事件属性的条件。条件可以是 IterativeConditions 或SimpleConditions。比如 SimpleCondition 可以像下面这样使用:
1 | start.where(new SimpleCondition<Event>() { |
组合 Pattern
前面已经对单个 Pattern 做了详细对讲解,接下来讲解如何将多个 Pattern 进行组合来完成一些需求。在完成组合 Pattern 之前需要定义第一个 Pattern,然后在第一个的基础上继续添加新的 Pattern。比如定义了第一个 Pattern 如下:
1 | Pattern<Event, ?> start = Pattern.<Event>begin("start"); |
接下来,可以为此指定更多的 Pattern,通过指定的不同的连接条件。比如:
- next():要求比较严格,该事件一定要紧跟着前一个事件。
- followedBy():该事件在前一个事件后面就行,两个事件之间可能会有其他的事件。
- followedByAny():该事件在前一个事件后面的就满足条件,两个事件之间可能会有其他的事件,返回值比上一个多。
- notNext():不希望前一个事件后面紧跟着该事件出现。
- notFollowedBy():不希望后面出现该事件。
具体怎么写呢,可以看下样例:
1 | Pattern<Event, ?> strict = start.next("middle").where(...); |
可能概念讲了很多,但是还是不太清楚,这里举个例子说明一下,假设有个 Pattern 是 a b,给定的数据输入顺序是 a c b b,对于上面那种不同的连接条件可能最后返回的值不一样。
- a 和 b 之间使用 next() 连接,那么则返回 {},即没有匹配到数据
- a 和 b 之间使用 followedBy() 连接,那么则返回 {a, b}
- a 和 b 之间使用 followedByAny() 连接,那么则返回 {a, b}, {a, b}
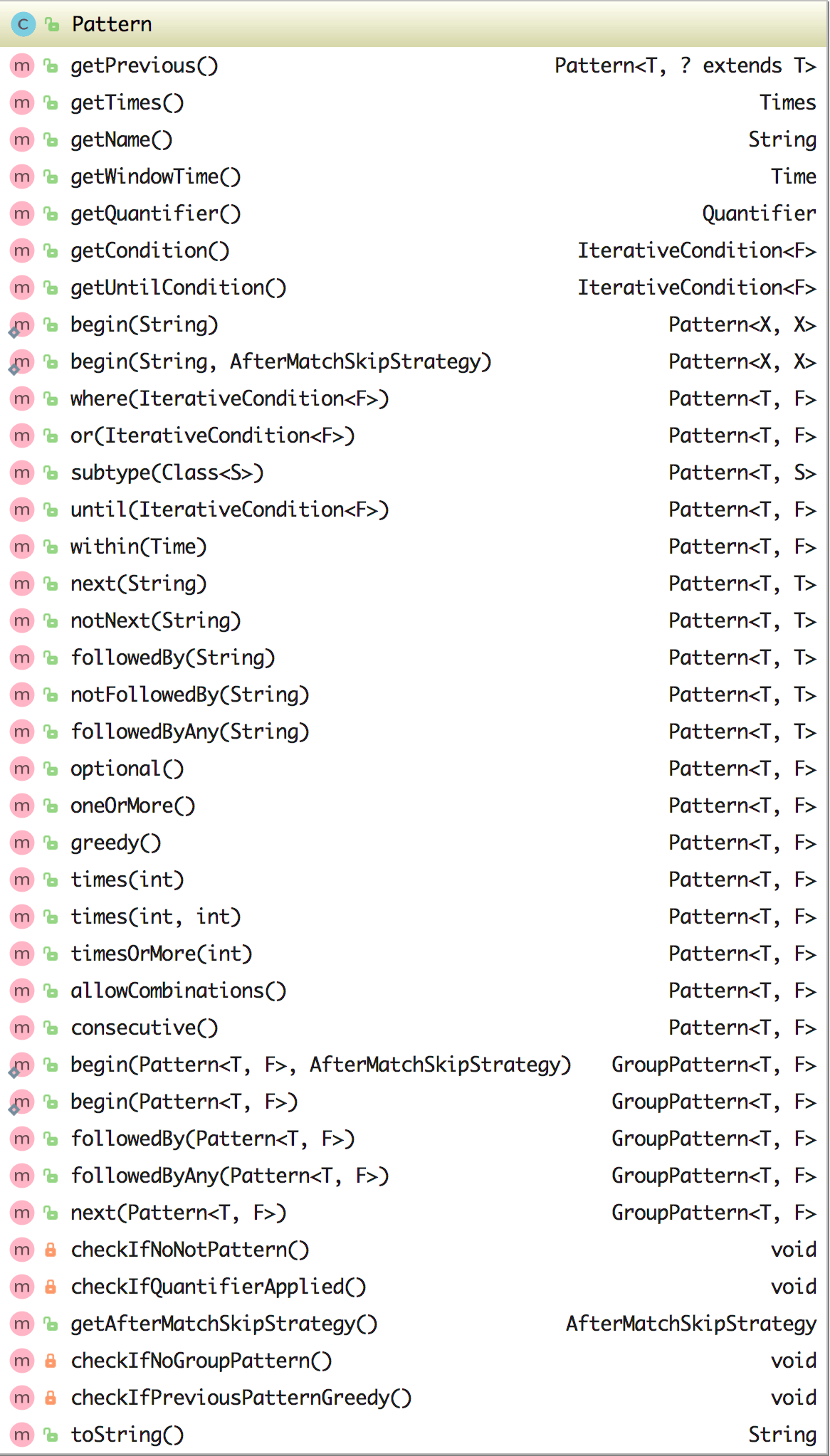
相信通过上面的这个例子讲解你就知道了它们的区别,尤其是 followedBy() 和 followedByAny(),笔者一开始也是毕竟懵,后面也是通过代码测试才搞明白它们之间的区别的。除此之外,还可以为 Pattern 定义时间约束。例如,可以通过 pattern.within(Time.seconds(10)) 方法定义此 Pattern 应该 10 秒内完成匹配。 该时间不仅支持处理时间还支持事件时间。另外还可以与 consecutive()、allowCombinations() 等组合,更多的请看下图中 Pattern 类的方法。
Group Pattern
业务需求比较复杂的场景,如果要使用 Pattern 来定义的话,可能这个 Pattern 会很长并且还会嵌套,比如由 begin、followedBy、followedByAny、next 组成和嵌套,另外还可以再和 oneOrMore()、times(#ofTimes)、times(#fromTimes, #toTimes)、optional()、consecutive()、allowCombinations() 等结合使用。效果如下面这种:
1 | Pattern<Event, ?> start = Pattern.begin( |
关于上面这些 Pattern 操作的更详细的解释可以查看官网。
事件匹配跳过策略
对于给定组合的复杂 Pattern,有的事件可能会匹配到多个 Pattern,如果要控制将事件的匹配数,需要指定跳过策略。在 Flink CEP 中跳过策略有四种类型,如下所示:
- NO_SKIP:不跳过,将发出所有可能的匹配事件。
- SKIP_TO_FIRST:丢弃包含 PatternName 第一个之前匹配事件的每个部分匹配。
- SKIP_TO_LAST:丢弃包含 PatternName 最后一个匹配事件之前的每个部分匹配。
- SKIP_PAST_LAST_EVENT:丢弃包含匹配事件的每个部分匹配。
- SKIP_TO_NEXT:丢弃以同一事件开始的所有部分匹配。
这几种策略都是根据 AfterMatchSkipStrategy 来实现的,可以看下它们的类结构图,如下所示:
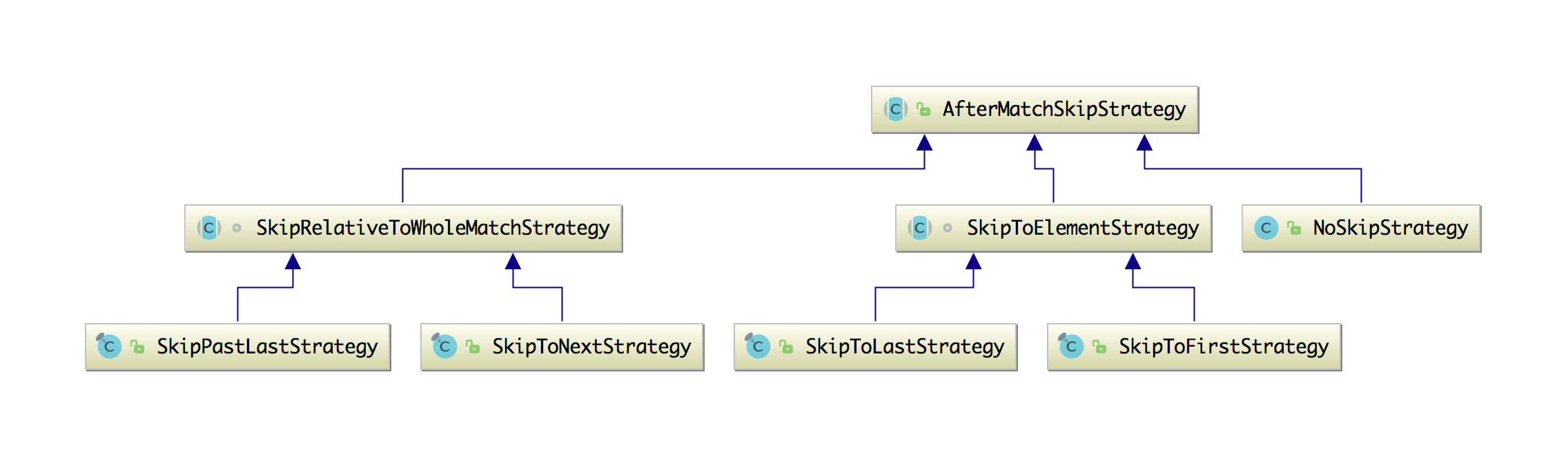
关于这几种跳过策略的具体区别可以查看官网,至于如何使用跳过策略,其实 AfterMatchSkipStrategy 抽象类中已经提供了 5 种静态方法可以直接使用,方法如下:

使用方法如下:
1 | AfterMatchSkipStrategy skipStrategy = ...; // 使用 AfterMatchSkipStrategy 调用不同的静态方法 |
检测 Pattern
编写好了 Pattern 之后,你需要的是将其应用在流数据中去做匹配。这时要做的就是构造一个 PatternStream,它可以通过 CEP.pattern(eventDataStream, pattern) 来获取一个 PatternStream 对象,在 CEP.pattern() 方法中,你可以选择传入两个参数(DataStream 和 Pattern),也可以选择传入三个参数 (DataStream、Pattern 和 EventComparator),因为 CEP 类中它有两个不同参数数量的 pattern 方法。
1 | public class CEP { |
选择 Pattern
在获取到 PatternStream 后,你可以通过 select 或 flatSelect 方法从匹配到的事件流中查询。如果使用的是 select 方法,则需要实现传入一个 PatternSelectFunction 的实现作为参数,PatternSelectFunction 具有为每个匹配事件调用的 select 方法,该方法的参数是 Map>,这个 Map 的 key 是 Pattern 的名字,在前面入门案例中设置的 start 和 middle 在这时就起作用了,你可以通过类似 get("start") 方法的形式来获取匹配到 start的所有事件。如果使用的是 flatSelect 方法,则需要实现传入一个 PatternFlatSelectFunction 的实现作为参数,这个和 PatternSelectFunction 不一致地方在于它可以返回多个结果,因为这个接口中的 flatSelect 方法含有一个 Collector,它可以返回多个数据到下游去。两者的样例如下:
1 | CEP.pattern(eventDataStream, pattern).select(new PatternSelectFunction<Event, String>() { |
关于 PatternStream 中的 select 或 flatSelect 方法其实可以传入不同的参数,比如传入 OutputTag 和 PatternTimeoutFunction 去处理延迟的数据,具体查看下图。
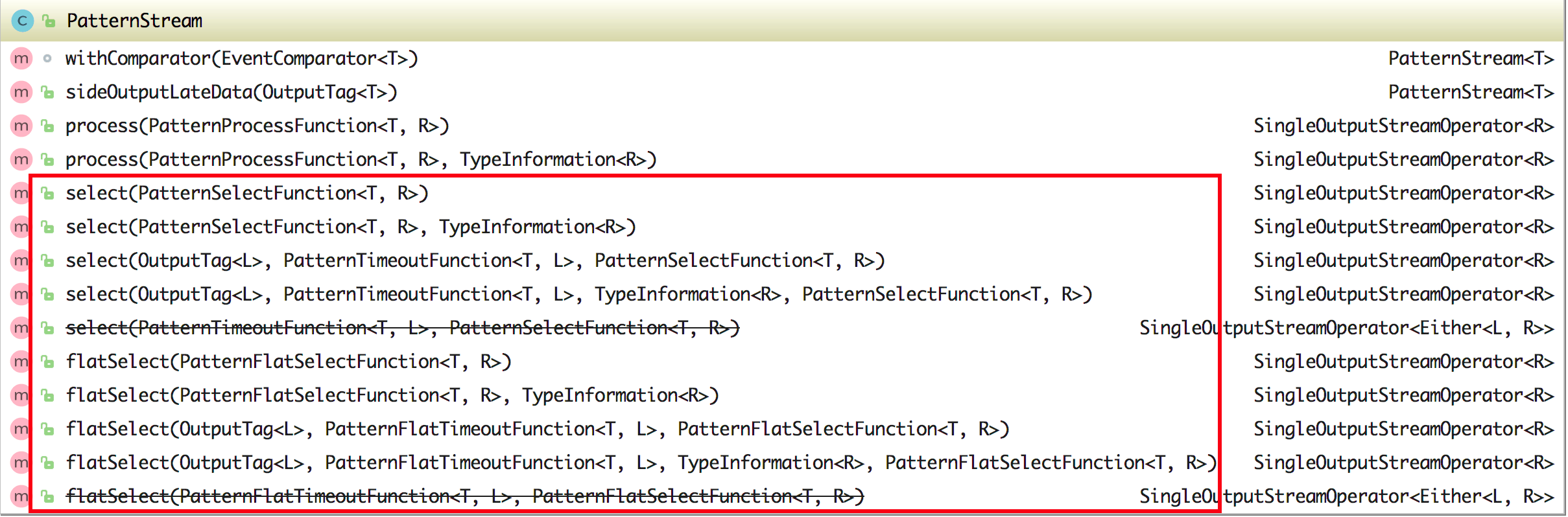
如果使用的 Flink CEP 版本是大于等于 1.8 的话,还可以使用 process 方法,在上图中也可以看到在 PatternStream 类中包含了该方法。要使用 process 的话,得传入一个 PatternProcessFunction 的实现作为参数,在该实现中需要重写 processMatch 方法。使用 PatternProcessFunction 比使用 PatternSelectFunction 和 PatternFlatSelectFunction 更好的是,它支持获取应用的的上下文,那么也就意味着它可以访问时间(因为 Context 接口继承自 TimeContext 接口)。另外如果要处理延迟的数据可以与 TimedOutPartialMatchHandler 接口的实现类一起使用。
CEP 时间属性
根据事件时间处理延迟数据
在 CEP 中,元素处理的顺序很重要,当时间策略设置为事件时间时,为了确保能够按照事件时间的顺序来处理元素,先来的事件会暂存在缓冲区域中,然后对缓冲区域中的这些事件按照事件时间进行排序,当水印到达时,比水印时间小的事件会按照顺序依次处理的。这意味着水印之间的元素是按照事件时间顺序处理的。
注意:当作业设置的时间属性是事件时间是,CEP 中会认为收到的水印时间是正确的,会严格按照水印的时间来处理元素,从而保证能顺序的处理元素。另外对于这种延迟的数据(和 3.5 节中的延迟数据类似),CEP 中也是支持通过 side output 设置 OutputTag 标签来将其收集。使用方式如下:
1 | PatternStream<Event> patternStream = CEP.pattern(inputDataStream, pattern); |
时间上下文
在 PatternProcessFunction 和 IterativeCondition 中可以通过 TimeContext 访问当前正在处理的事件的时间(Event Time)和此时机器上的时间(Processing Time)。你可以查看到这两个类中都包含了 Context,而这个 Context 继承自 TimeContext,在 TimeContext 接口中定义了获取事件时间和处理时间的方法。
1 | public interface TimeContext { |


