在大数据计算场景,无论使用 MapReduce、Spark 还是 Flink 计算框架,无论是批处理还是流处理都存在数据倾斜的问题,通过本节学习产生数据倾斜的原因及如何在生产环境解决数据倾斜。
数据倾斜简介
分析一个计算各 app PV 的案例,如下图所示,圆球表示 app1 的日志,方块表示 app2 的日志,Source 端从外部系统读取用户上报的各 app 行为日志,要计算各 app 的 PV,所以按照 app 进行 keyBy,相同 app 的数据发送到同一个 Operator 实例中处理,keyBy 后对 app 的 PV 值进行累加来,最后将计算的 PV 结果输出到外部 Sink 端。

可以看到在任务运行过程中,计算 Count 的算子有两个并行度,其中一个并行度处理 app1 的数据,另一个并行度处理 app2 的数据。由于 app1 比较热门,所以 app1 的日志量远大于 app2 的日志量,造成计算 app1 PV 的并行度压力过大成为整个系统的瓶颈,而计算 app2 PV 的并行度数据量较少所以 CPU、内存以及网络资源的使用率整体都比较低,这就是产生数据倾斜的案例。
判断是否存在数据倾斜
这里再通过一个案例来讲述 Flink 任务如何来判断是否存在数据倾斜,如下图所示,是 Flink Web UI Job 页面展示的任务执行计划,可以看到任务经过 Operator Chain 后,总共有两个 Task,上游 Task 将数据 keyBy 后发送到下游 Task,如何判断第二个 Task 计算的数据是否存在数据呢?
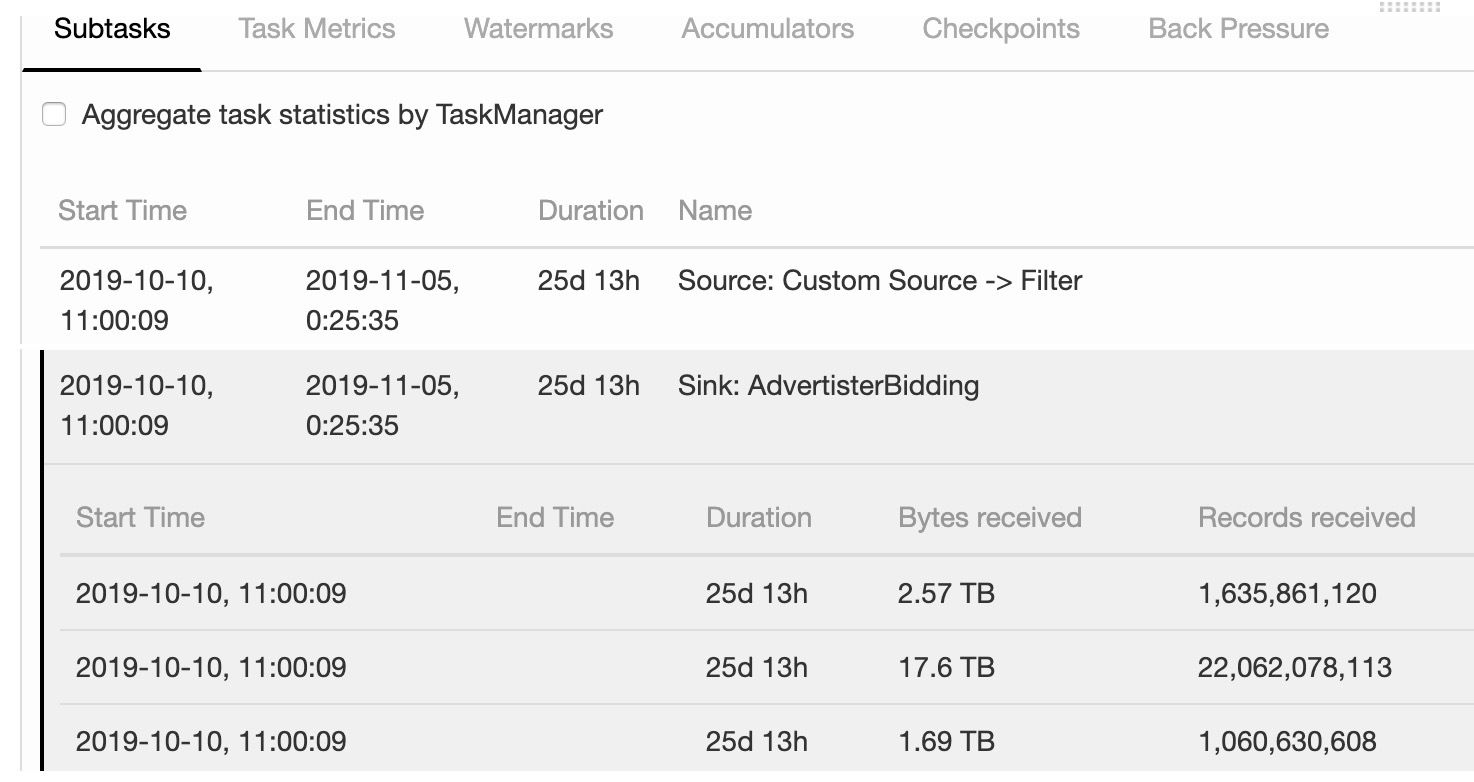
如下图所示,通过 Flink Web UI 中 Job 页面的第一个 Subtasks 选项卡,可以看到任务的两个 Task,点击 Task,可以看到 Task 相应的 Subtask 详情。例如 Subtask 的启动时间、结束时间、持续时长、接收数据量的字节数以及接收数据的个数。图中可以看到,相同 Task 的多个 Subtask 中,有的 Subtask 接收到 1.69 TB 的数据量,有的 Subtask 接收到 17.6 TB 的数据量,通过 Flink Web UI 可以精确地看到每个 Subtask 处理了多少数据,即可判断出 Flink 任务是否存在数据倾斜,接下来学习 Flink 中如何来解决数据倾斜。
分析和解决数据倾斜问题
在 Flink 中,很多因素都会导致数据倾斜,例如 9.6.1 节描述的 keyBy 后的聚合操作存在数据倾斜。keyBy 之前的数据直接来自于数据源,一般不会出现数据倾斜,除非数据源中的数据发生了数据倾斜。本小节将从多个角度来解决数据倾斜。
keyBy 后的聚合操作存在数据倾斜
Flink 社区关于数据倾斜的解决方案炒得最热的也莫过于 LocalKeyBy 了。Flink 中数据倾斜一般发生于 keyBy 之后的聚合操作,LocalKeyBy 的思想是:在 keyBy 上游算子数据发送之前,首先在上游算子的本地对数据进行聚合后再发送到下游,使下游接收到的数据量大大减少,从而使得 keyBy 之后的聚合操作不再是任务的瓶颈。
如下图所示,Source 算子向下游发送数据之前,首先对数据进行预聚合,Source Subtask 0 预聚合后,圆圈 PV 值为 5、方块 PV 值为 2,Source Subtask 1 预聚合后,圆圈 PV 值为 6、方块 PV 值为 1。keyBy 后,Count 算子进行 PV 值的累加,计算圆圈 PV 的 Subtask 接收到 5 和 6,只需要将 5+6 即可计算出圆圈总 PV 值为 11,计算方块 PV 的 Subtask 接收到 2 和 1,只需要将 2 +1 即可计算出方块总 PV 值为 3,最后将圆圈和方块的 PV 结果输出到 Sink 端即可。

使用该方案计算 PV,带来了两个非常大的好处。
- 在上游算子中对数据进行了预聚合,因此大大减少了上游往下游发送的数据量,从而减少了网络间的数据传输,节省了集群的带宽资源。上图案例中如果不聚合,上游需要往下游发送 14 条数据,聚合后仅仅需要发送 4 条数据即可。如果上游算子接收 1 万条数据后聚合一次,那么数据的压缩比会更大,优化效果会更加明显。
- 下游拿到的直接是上游聚合好的中间结果,因此下游 Count 算子计算的数据量大大减少,而且 Count 算子不再会有数据倾斜的问题。
上游算子相比之前多了一个聚合的工作,所以压力必然会增加,但是只要数据源不发生数据倾斜,那么上游 Source 算子的各并行度之间的负载就会比较均衡。
这里就是 MapReduce 中 Combiner 的思想嘛,在 Map 端对数据进行预聚合之后,再将预聚合后的数据发送到 Reduce 端去处理,从而大大减少了 shuffle 的数据量。
虽然思想一样,但 Flink 流处理的预聚合相比 MapReduce 的批处理而言,带来了一个新的挑战:Flink 是天然的流式处理,即来一条数据处理一条(这里不考虑 Flink 网络传输层的 Buffer 机制),但是聚合操作要求必须是多条数据或者一批数据才能聚合,单条数据没有办法通过聚合来减少数据量。
所以从 Flink LocalKeyBy 实现原理来讲,必然会存在一个积攒批次的过程,在上游算子中必须攒够一定的数据量,对这些数据聚合后再发送到下游。既然是积攒批次,那肯定有一个积攒批次的策略,上图案例可以理解为每个批次 7 条数据,当读取到 7 条数据后,将这 7 条数据聚合后发送到下游。
具体实现逻辑是:内存里维护一个计数器,每来一条数据计数器加一,并将数据聚合放到内存 Buffer 中,当计数器到达 7 时,将内存 Buffer 中的数据发送到下游、计数器清零、Buffer 清空。
1 | class LocalKeyByFlatMap extends FlatMapFunction<String, Tuple2<String, Long>> { |
代码逻辑比较简单,使用了 FlatMap 算子来做缓冲,每来一条数据都需要检索,为了提高检索效率,所以这里使用 HashMap 类型的 localPvStat 用来做 Buffer 来缓存数据,currentSize 记录当前批次已经往 localPvStat 中写入的数据量。在 LocalKeyByFlatMap 构造器中需要初始化 batchSize,即批次大小。flatMap 方法将新数据添加到 localPvStat 中,currentSize 进行加一操作,且 currentSize 加一后如果大于 batchSize 则表示当前批次的数据已经够了,需要将数据发送到下游,则遍历 localPvStat,将 Buffer 中的数据发送到下游,并将 localPvStat 清空且 currentSize 清零。
代码逻辑简单易懂,但是问题又来了,在积攒批次的过程中,如果发生故障,Flink 任务能保障 Exactly Once 吗?
直接给出答案:不能保证 Exactly Once,可能会丢数据,为什么呢?
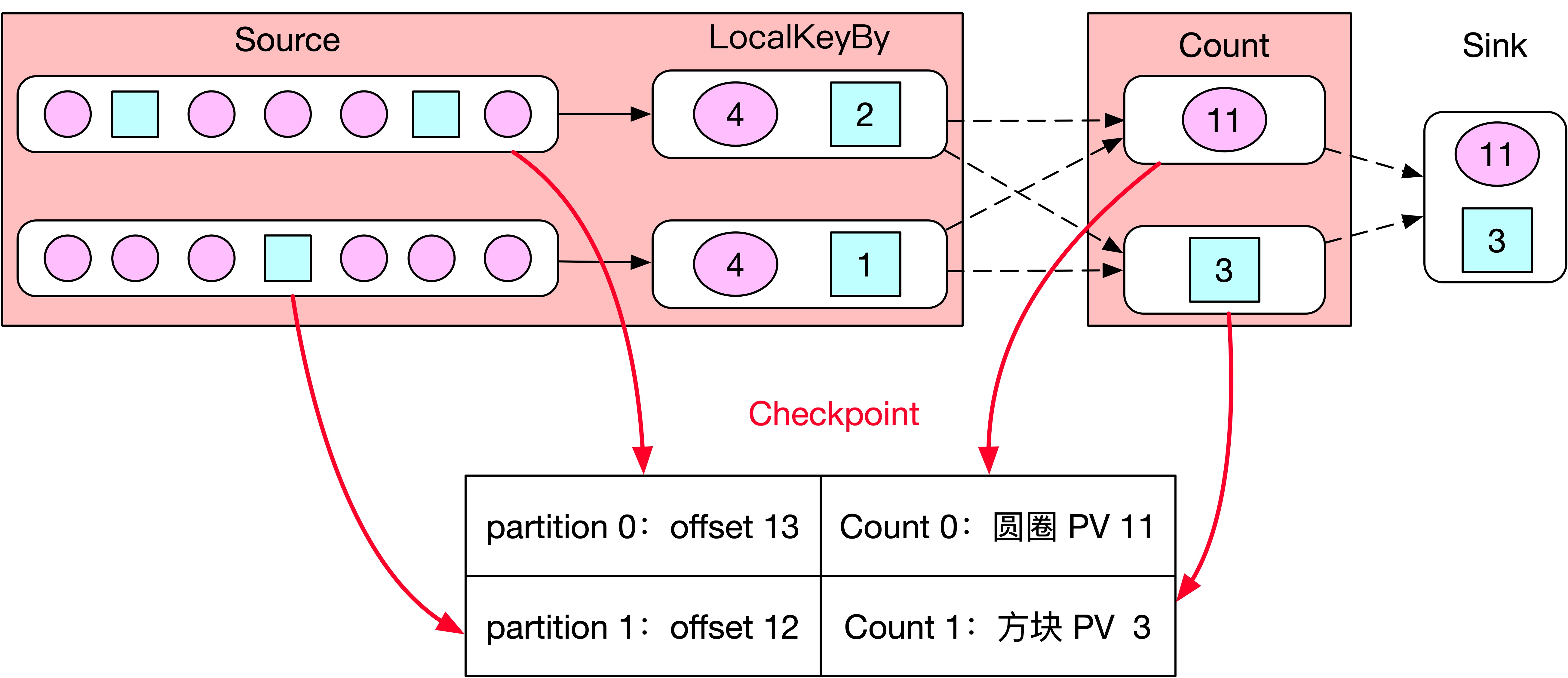
如下图所示,batchSize 设置的 7,但是当 JobManager 触发 Checkpoint 的时候,Source Subtask 0 消费到 offset 为 13 的位置、Source Subtask 1 消费到 offset 为 12 的位置,所以 Source 0 会将 offset=13 保存到状态后端,Source 1 会将 offset=12 保存到状态后端。接着 Checkpoint barrier 跟随着数据往下游发送到 LocalKeyBy,此时 LocalKeyBy 0 的 Buffer 中只有 6 条数据、LocalKeyBy 1 的 Buffer 中只有 5 条数据,所以 LocalKeyBy 0 和 1 都不会将数据发送到下游。但是 barrier 会接着往下游传递到 Count 算子,Count 算子会对自身状态信息进行快照,Count 0 会将圆圈 PV=11 保存到状态后端、Count 1 会将圆圈 PV=3 保存到状态后端,各 task 向 JobManager 反馈,最后 Checkpoint 成功了,紧接着数据正常开始处理。
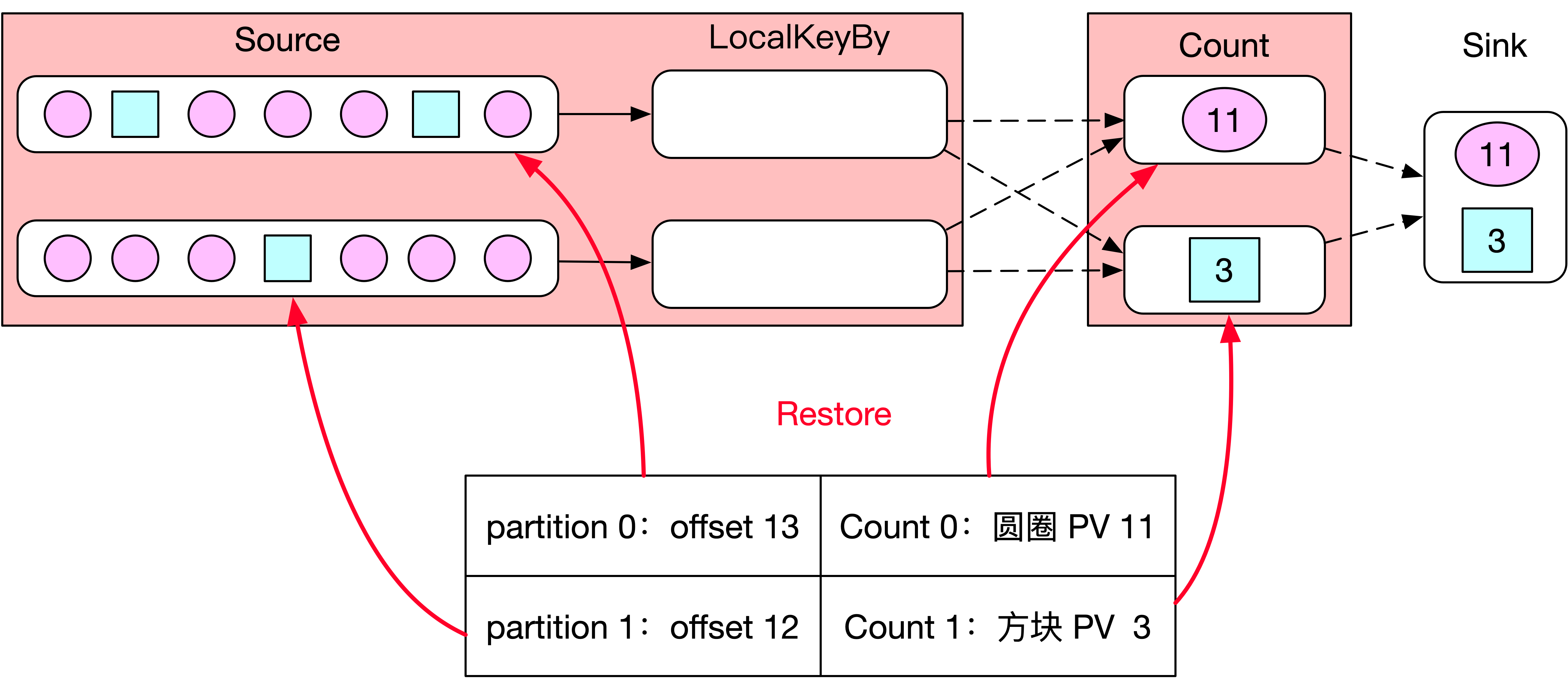
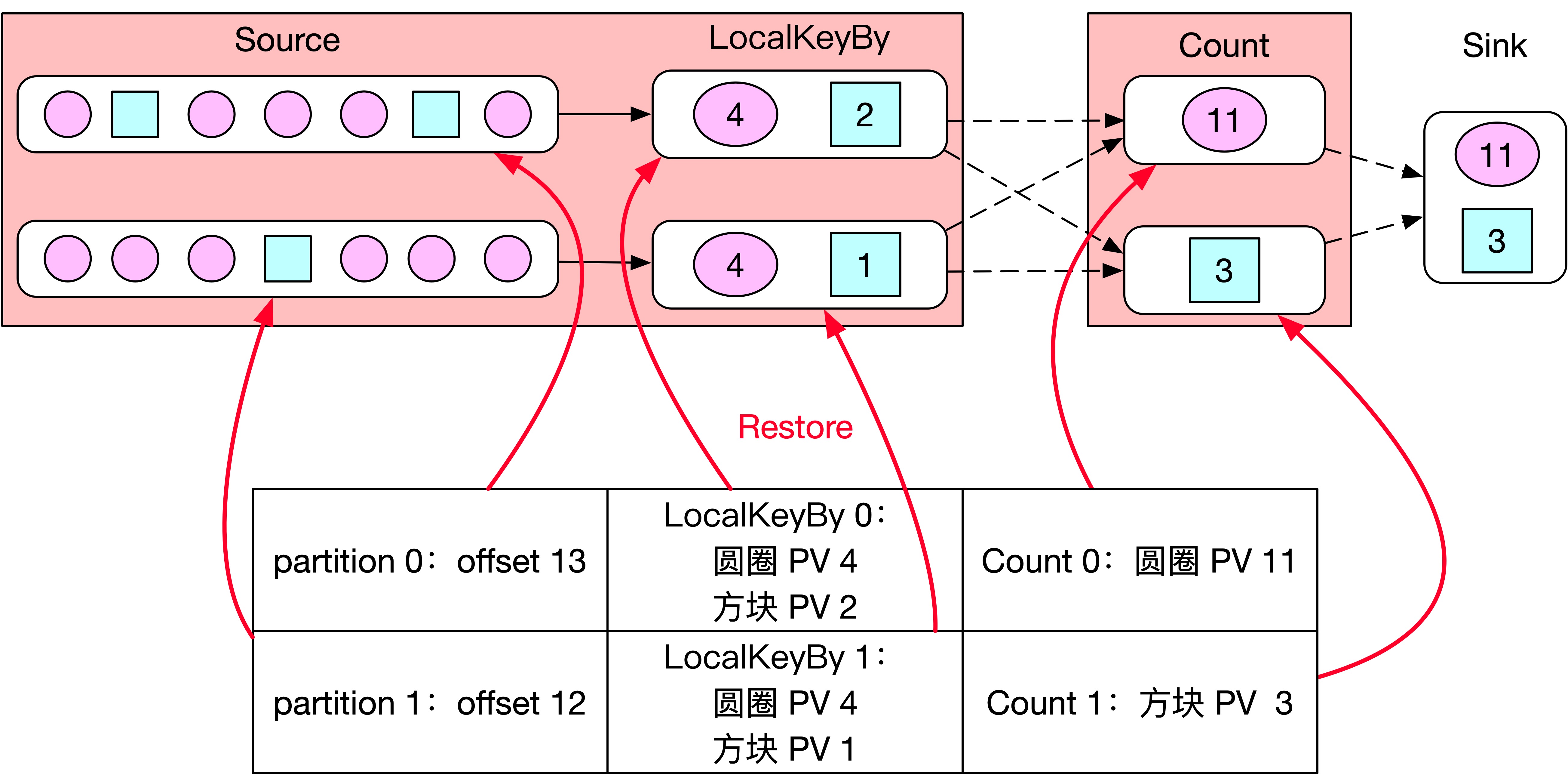
数据正常处理一段时间后,由于机器故障 Flink 任务突然挂了,如下图所示,Flink 任务会从状态恢复,Source Subtask 0 从 offset 为 13 的位置开始消费 Kafka,Source Subtask 1 从 offset 为 12 的位置开始消费 Kafka。Count 0 恢复后保存圆圈的 PV 为 11,Count 1 恢复后保存方块的 PV 为 3。此时任务从状态中恢复完成,正常开始处理数据,请问 Flink 任务从状态恢复后丢数据了吗?
丢了,因为 Source 0 对应的 offset 13 表示 Source 0 消费了 13 条数据,但是其中有 6 条数据缓存在 LocalKeyBy 0 的 Buffer 中没及时发送到下游,所以这 6 条数据丢了,同理 Source 1 对应的 offset 12 表示 Source 1 消费了 12 条数据,其中还有 5 条数据缓存在 LocalKeyBy 1 的 Buffer 中没及时发送到下游,所以这 5 条数据也丢了。
通过上述详细案例分析,知道了我们设计的 LocalKeyBy 虽然能够提高性能,但存在丢数据的风险。,Flink 虽然支持 Exactly Once,但不是说你的代码随便瞎写 Flink 也能保证 Exactly Once,做为使用 Flink 的一员,我们应该根据原理书写出能保证 Flink Exactly Once 的代码。
上述方案该如何完善才能保证 Exactly Once 呢?在 Checkpoint 时上述方案会把 LocalKeyBy 算子 Buffer 中的数据丢弃,所以重点应该是如何来保证 LocalKeyBy 算子 Buffer 中的数据不丢。在 Checkpoint 时可以将 Buffer 中还未发送到下游的数据保存到 Flink 的状态中,这样当 Flink 任务从 Checkpoint 处恢复时,可以将那些在 Buffer 中的数据从状态后端恢复。如下图所示,相比上述方案,Checkpoint 时会将 LocalKeyBy 算子 Buffer 中的数据也保存到状态后端。
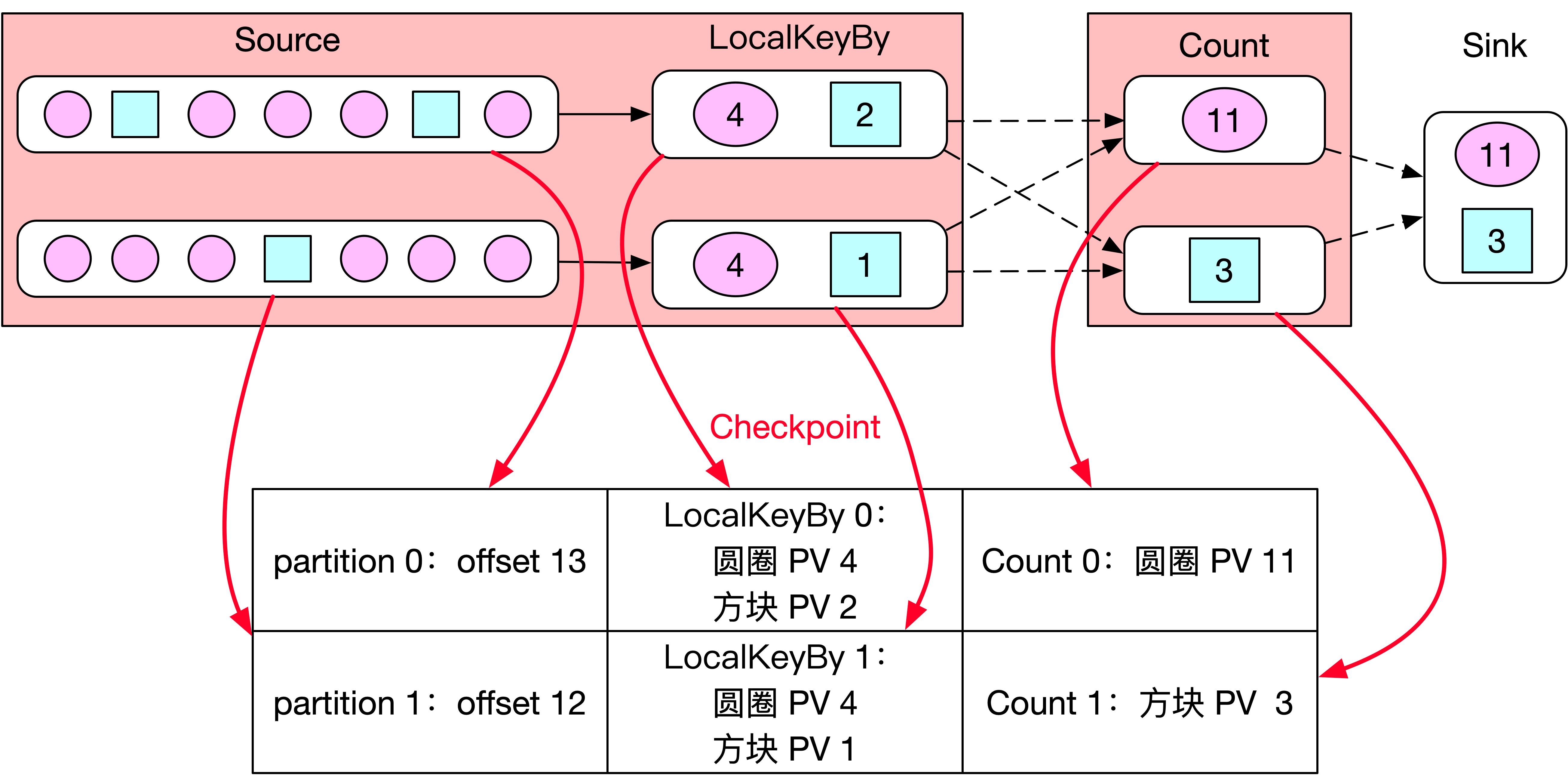
如下图所示,当 Flink 任务从 Checkpoint 处恢复时,不仅恢复 offset 信息和 PV 信息,还需要把 LocalKeyBy 算子 Buffer 中的数据恢复,这样就可以保证不丢数据了。
具体代码如何实现呢?Checkpoint 时 LocalKeyBy 算子可能还有缓冲的数据没发送到下游,为了保证 Exactly Once,这里需要将 Buffer 中的数据保存在状态中。
Flink 有两种 State 分别是 OperatorState 和 KeyedState,OperatorState 是一个 Operator 实例对应一个State,KeyedState 是每个 key 对应一个 State,KeyedState 只能作用于 keyby 算子之后的 KeyedStream。
上图中我们可以看出,LocalKeyBy 算子位于 keyBy 算子之前,因此 LocalKeyBy 算子内部不能使用 KeyedState,只能使用 OperatorState,且 OperatorState 只支持一种数据结构,即 ListState,所以这里 buffer 中的数据只能保存在 OperatorState 类型的 ListState 中。当 Checkpoint 时,需要将内存 buffer 中的数据添加到 ListState,状态中需要保存 KV 类型的数据,key 是 appId、value 是 app 对应的 PV 值。
这里为了在 ListState 中保存 KV 格式的数据,需要将 buffer 中 KV 类型的数据转化为 Tuple2 类型后再添加到 ListState 中。代码具体实现如下所示:
1 | class LocalKeyByFlatMap extends RichFlatMapFunction<String, Tuple2<String, Long>> implements CheckpointedFunction { |
上述改进方案后的 LocalKeyByFlatMap 相比之前方案仅仅增加了一个属性,即:ListState> 类型的 localPvStatListState 用来存放 Checkpoint 时 buffer 中那些可能丢失的数据。在 snapshotState 方法中将 buffer 中的数据保存到状态中,在 initializeState 方法中将状态中恢复的数据 put 到 buffer 中并初始化计数器 currentSize。代码相对比较简答,容易看懂。
请问上述代码能保障 buffer 中的数据不丢吗?如果不修改 Source Task 和 LocalKeyByFlatMap 算子的并行度,理论来讲可以保证 Exactly Once,但是一旦修改并行度,还能保证 Exactly Once 吗?当并行度降低后,getOperatorStateStore().getListState() 恢复 ListState 时,会把 ListState 中的状态信息均匀分布到各个 Operator 实例中。当上述案例中 LocalKeyBy 的并行度从 2 调节为 1 时,数据恢复如下图所示:

首先 Source 端 partition 0 和 partition 1 的 offset 信息恢复没有问题,Count 算子圆圈和方块的 PV 信息恢复也没有问题。关键在于 LocalKeyBy 算子中 PV 信息恢复时会丢数据吗?状态恢复时,从状态中将 PV 信息恢复到 buffer 中的核心代码如下所示:
1 | // 从状态中恢复数据到 localPvStat 中 |
从状态中会恢复 4 个 Tuple2,分别是 <圆圈,4>、<方块,2>、<圆圈,4>、<方块,1>,这里有两个圆圈、两个方块,恢复到 HashMap 类型的 localPvStat,HashMap 中相同的 key 不能重复,所以 HashMap 中不可能保存两个圆圈和两个方块。恢复时 app 相同的数据,应该将其 PV 值累加,所以恢复的结果应该是 <圆圈,8>、<方块,3>。但是上述代码,仅仅是覆盖操作,假如遍历状态时返回的顺序为 <圆圈,4>、<方块,2>、<圆圈,4>、<方块,1>,那么上述恢复流程为:将上述元素依次 put 到 HashMap 中,所以 HashMap 类型的 buffer 恢复完数据后,buffer 中保存的 PV 信息为 <圆圈,4>、<方块,1>。显然恢复过程中的覆盖操作将状态数据 <圆圈,4>、<方块,2> 丢了,所以上述方案如果不修改并行度时,不会丢数据,如果修改并行度时,可能会丢数据。
在使用状态来保证 Exactly Once 时,必须考虑修改并行度后,状态如何正常恢复的情况。优化后的代码如下所示,仅仅修改 initializeState 方法中恢复状态的逻辑:
1 | // 从状态中恢复 buffer 中的数据 |
代码中,首先从 buffer 中获取当前 app 的 PV 数据,如果 buffer 中不包含当前 app 则 PV 值返回 0,如果 buffer 中包含了当前 app 则返回相应的 PV 值,将 buffer 中的 pv 加当前的 pv,put 到 buffer 中即可保证恢复时不丢数据。
到这里 LocalKeyBy 的思路及具体代码实现都讲完了,也带着大家分析了多种可能丢数据的情况,并一一解决。上述完整的代码实现请参阅。上述代码实现有个局限性,就是需要了解业务,按照下游的聚合逻辑,在上游 keyBy 之前同样也需要实现一遍。关于通用的 LocalKeyBy 实现,Flink 源码中目前还没有此功能,对具体实现原理感兴趣的可以参阅腾讯杨华老师贡献的 FLIP-44。
keyBy 之前发生数据倾斜
上一部分分析了 keyBy 后由于数据本身的特征可能会发生数据倾斜,可以在 keyBy 之前进行一次预聚合,从而使得 keyBy 后的数据量大大降低。但是如果 keyBy 之前就存在数据倾斜呢?这样上游算子的某些实例可能处理的数据较多,某些实例可能处理的数据较少,产生该情况可能是因为数据源的数据本身就不均匀,例如由于某些原因 Kafka 的 topic 中某些 partition 的数据量较大,某些 partition 的数据量较少。对于不存在 keyBy 的 Flink 任务也会出现该情况,解决思路都一样,主要在于没有 shuffle 的 Flink 任务如何来解决数据倾斜。对于这种情况,需要让 Flink 任务强制进行 shuffle。如何强制 shuffle 呢?了解一下 DataStream 的物理分区策略。
| 分区策略 | 描述 |
|---|---|
| dataStream.partitionCustom(partitioner, “someKey”); dataStream.partitionCustom(partitioner, 0); | 根据指定的字段进行分区,指定字段值相同的数据发送到同一个 Operator 实例处理 |
| dataStream.shuffle(); | 将数据随机地分配到下游 Operator 实例 |
| dataStream.rebalance(); | 使用轮循的策略将数据发送到下游 Operator 实例 |
| dataStream.rescale(); | 基于 rebalance 优化的策略,依然使用轮循策略,但仅仅是 TaskManager 内的轮循,只会在 TaskManager 本地进行 shuffle 操作,减少了网络传输 |
| dataStream.broadcast(); | 将数据广播到下游所有的 Operator 实例 |
在这里需要解决数据倾斜,只需要使用 shuffle、rebalance 或 rescale 即可将数据均匀分配,从而解决数据倾斜的问题。


