FlinkKafkaConsumer 做为 Source,从 Kafka 读取数据到 Flink 中,首先想一下设计 FlinkKafkaConsumer,需要考虑哪些?
分析 FlinkKafkaConsumer 的设计思想
FlinkKafkaConsumer 做为 Source,从 Kafka 读取数据到 Flink 中,首先想一下设计 FlinkKafkaConsumer,需要考虑哪些?
- Flink 中 kafka 的 offset 保存在哪里,具体如何保存呢?任务重启恢复时,如何读取之前消费的 offset?
- 如果 Source 端并行度改变了,如何来恢复 offset?
- 如何保证每个 FlinkKafkaConsumer 实例消费的 partition 负载均衡?如何保证不出现有的实例消费 5 个 kafka partition,有的实例仅消费 1 个 kafka partition?
- 当前消费的 topic 如果动态增加了 partition,Flink 如何实现自动发现并消费?
带着这些问题来看一看 FlinkKafkaConsumer 是怎么解决上述问题的。
Kafka offset 存储及如何实现 Consumer 实例消费 partition 的负载均衡
Flink 将任务恢复需要的信息都保存在状态中,当然 Kafka 的 offset 信息也保存在 Flink 的状态中,当任务从状态中恢复时会从状态中读取相应的 offset,并从 offset 位置开始消费。
在 Flink 中有两个基本的 State:Keyed State 和 Operator State。
- Keyed State 只能用于 KeyedStream 的 function 和 Operator 中,一个 Key 对应一个 State;
- 而 Operator State 可以用于所有类型的 function 和 Operator 中,一个 Operator 实例对应一个 State,假如一个算子并行度是 5 且使用 Operator State,那么这个算子的每个并行度都对应一个 State,总共 5 个 State。
FlinkKafkaConsumer 做为 Source 只能使用 Operator State,Operator State 只支持一种数据结构 ListState,可以当做 List 类型的 State。所以 FlinkKafkaConsumer 中,将状态保存在 Operator State 对应的 ListState 中。具体如何保存呢?需要先了解每个 FlinkKafkaConsumer 具体怎么消费 Kafka。
对于同一个消费者组,Kafka 要求 topic 的每个 partition 只能被一个 Consumer 实例消费,相反一个 Consumer 实例可以去消费多个 partition。当 Flink 消费 Kafka 时,出现了以下三种情况:
| 情况 | 现象 |
|---|---|
| FlinkKafkaConsumer 并行度大于 topic 的 partition 数 | 有些 FlinkKafkaConsumer 不会消费 Kafka |
| FlinkKafkaConsumer 并行度等于 topic 的 partition 数 | 每个 FlinkKafkaConsumer 消费 1 个 partition |
| FlinkKafkaConsumer 并行度小于 topic 的 partition 数 | 每个 FlinkKafkaConsumer 至少消费 1 个 partition,可能会消费多个 partition |
Flink 是如何为每个 Consumer 实例合理地分配去消费哪些 partition 呢?源码中 KafkaTopicPartitionAssigner 类的 assign 方法,负责分配 partition 给 Consumer 实例。assign 方法的输入参数为 KafkaTopicPartition 和 Consumer 的并行度,KafkaTopicPartition 主要包含两个字段:String 类型的 topic 和 int 类型的 partition。assign 方法返回该 KafkaTopicPartition 应该分配给哪个 Consumer 实例去消费。假如 Consumer 的并行度为 5,表示包含了 5 个 subtask,assign 方法的返回值范围为 0~4,分别表示该 partition 分配给 subtask0-subtask4。
1 | /** |
assign 方法是如何给 KafkaTopicPartition 分配 Consumer 实例的呢?
第一行代码根据 topic name 的 hashCode 运算后对 subtask 的数量求余生成一个 startIndex,第二行代码用 startIndex + partition 编号对 subtask 的数量求余,可以保证该 topic 的 0 号 partition 分配给 startIndex 对应的 subtask,后续的 partition 依次分配给后续的 subtask。
例如,名为 “test-topic” 的 topic 有 11 个 partition 分别为 partition0-partition10,Consumer 有 5 个并行度分别为 subtask0-subtask4。计算后的 startIndex 为 1,表示 partition0 分配给 subtask1,partition1 分配给 subtask2 以此类推,subtask 与 partition 的对应关系如下图所示。
assign 方法给 partition 分配 subtask 实际上是轮循的策略,首先计算一个起点 startIndex 分配给 partition0,后续的 partition 轮循地分配给 subtask,从而使得每个 subtask 消费的 partition 得以均衡。
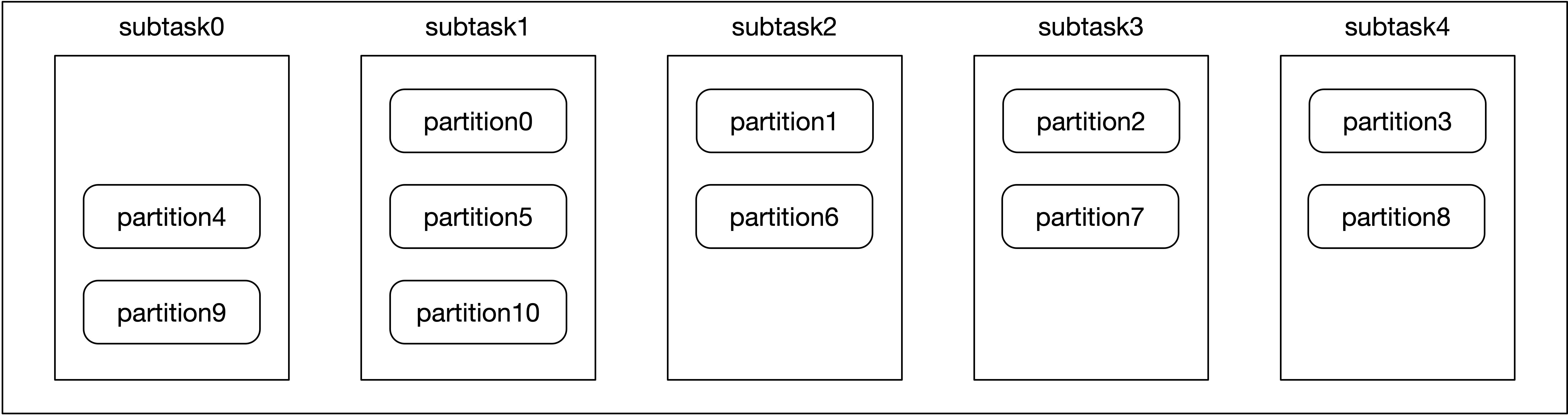
每个 subtask 只负责一部分 partition,所以在维护 partition 的 offset 信息时,每个 subtask 只需要将自己消费的 partition 的 offset 信息保存到状态中即可。
保存的格式理论来讲应该是 kv 键值对,key 为 KafkaTopicPartition,value 为 Long 类型的 offset 值。但 Flink 的 Operator State 只支持 ListState 一种数据结构,不支持 kv 格式,可以将 KafkaTopicPartition 和 Long 封装为 Tuple2<KafkaTopicPartition, Long> 存储到 ListState 中。如下所示,Flink 源码中确实如此,使用 ListState<Tuple2<KafkaTopicPartition, Long>> 类型的 unionOffsetStates 来保存 Kafka 的 offset 信息。
1 | /** Accessor for state in the operator state backend. */ |
当 Flink 应用从 Checkpoint 恢复任务时,会从 unionOffsetStates 中读取上一次 Checkpoint 保存的 offset 信息,并从 offset 的位置开始继续消费,从而实现 Flink 任务的故障容错。例如,任务重启后,Operator State 是一个 Operator 实例对应一个 State,subtask0 依然消费 partition4 和 partition9,subtask0 从自己的 State 中可以读取到 partition4 和 partition9 消费的 offset,从 offset 位置接着往后消费即可。问题来了,若 FlinkKafkaConsumer 的并行度改变后,offset 信息如何恢复呢?
Source 端并行度改变了,如何来恢复 offset
subtask1 当前消费了 3 个 partition,而其他 subtask 仅消费 2 个 partition,当发现 subtask1 读取 Kafka 成为瓶颈后,需要调大 Consumer 的并行度,使得每个 subtask 最多仅消费 2 个 partition。将 Consumer 实例的并行度增大到 6 以后,分配器对 partition 重新分配给 6 个 subtask,计算后的 startIndex 为 0,表示 partition0 分配给 subtask0,后续的 partition 采用轮循策略,partition 与 subtask 的对应关系如下。
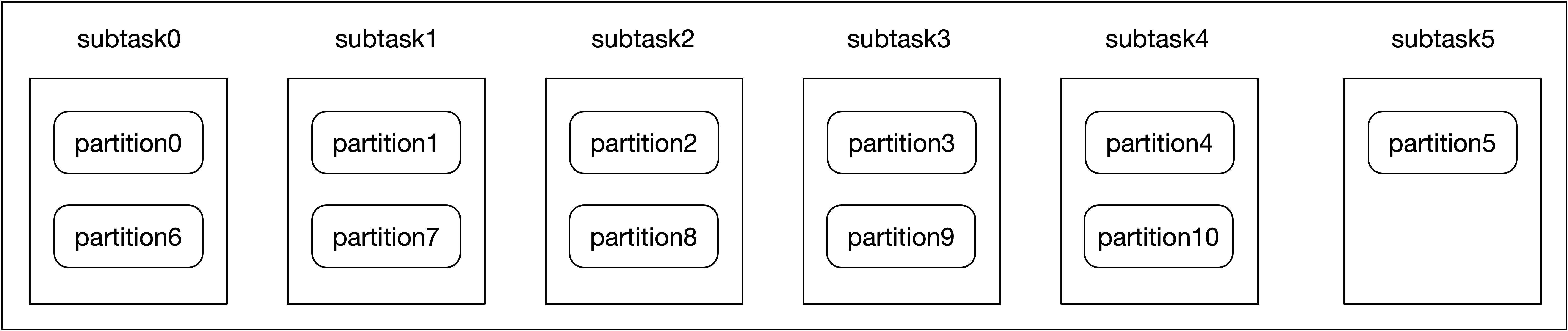
之前 subtask0 消费 partition 4 和 9,并行度调大以后,subtask0 被分配消费 partition 0 和 6。但是 Flink 任务从 Checkpoint 恢复后,能保证 subtask0 读取到 partition 0 和 6 的 offset 吗?这个就需要深入了解当 Flink 算子并行度改变后,Operator State 的 ListState 两种恢复策略。两种策略如下所示,在 initializeState 方法中执行相应 API 来恢复。
1 | OperatorStateStore stateStore = context.getOperatorStateStore(); |
当并行度改变后,getListState 恢复策略是均匀分配,将 ListState 中保存的所有元素均匀地分配到所有并行度中,每个 subtask 获取到其中一部分状态信息。
getUnionListState 策略是将所有的状态信息合并后,每个 subtask 都获取到全量的状态信息。在 FlinkKafkaConsumer 中,假如使用 getListState 来获取 ListState,采用均匀分配状态信息的策略,Flink 可能给 subtask0 分配了 partition0 和 partition1 的 offset 信息,但实际上分配器让 subtask0 去消费 partition0 和 partition6,此时 subtask0 并拿不到 partition 6 的 offset 信息,不知道该从 partition 6 哪个位置消费,所以均匀分配状态信息的策略并不能满足需求。
这里应该使用 getUnionListState 来获取 ListState,也就是说每个 subtask 都可以获取到所有 partition 的 offset 信息,然后根据分配器让 subtask 0 去消费 partition0 和 partition6 时,subtask0 只需要从全量的 offset 中拿到 partition0 和 partition6 的状态信息即可。
这么做会使得每个 subtask 获取到一些无用的 offset 的信息,但实际上这些 offset 信息占用的空间会比较小,所以该方案成本比较低。关于 OperatorState 的 ListState 两种获取方式请参考代码:
FlinkKafkaConsumer 初始化时,恢复 offset 相关的源码如下:
1 | // initializeState 方法中用于恢复 offset 状态信息 |
对 offset 信息快照相关的源码如下:
1 | public final void snapshotState(FunctionSnapshotContext context) throws Exception { |
上述源码分析描述了,当 Checkpoint 时 FlinkKafkaConsumer 如何将 offset 信息保存到状态中,当任务从 Checkpoint 处恢复时 FlinkKafkaConsumer 如何从状态中获取相应的 offset 信息,并解答了当 Source 并行度改变时 FlinkKafkaConsumer 如何来恢复 offset 信息。
如何实现自动发现当前消费 topic 下新增的 partition
当 FlinkKafkaConsumer 初始化时,每个 subtask 会订阅一批 partition,但是当 Flink 任务运行过程中,如果被订阅的 topic 创建了新的 partition,FlinkKafkaConsumer 如何实现动态发现新创建的 partition 并消费呢?
在使用 FlinkKafkaConsumer 时,可以通过 Properties 传递一些配置参数,当配置了参数FlinkKafkaConsumerBase.KEY_PARTITIONDISCOVERY_INTERVALMILLIS 时,就会开启 partition 的动态发现,该参数表示间隔多久检测一次是否有新创建的 partition。那具体实现原理呢?相关源码的 UML 图如下所示:
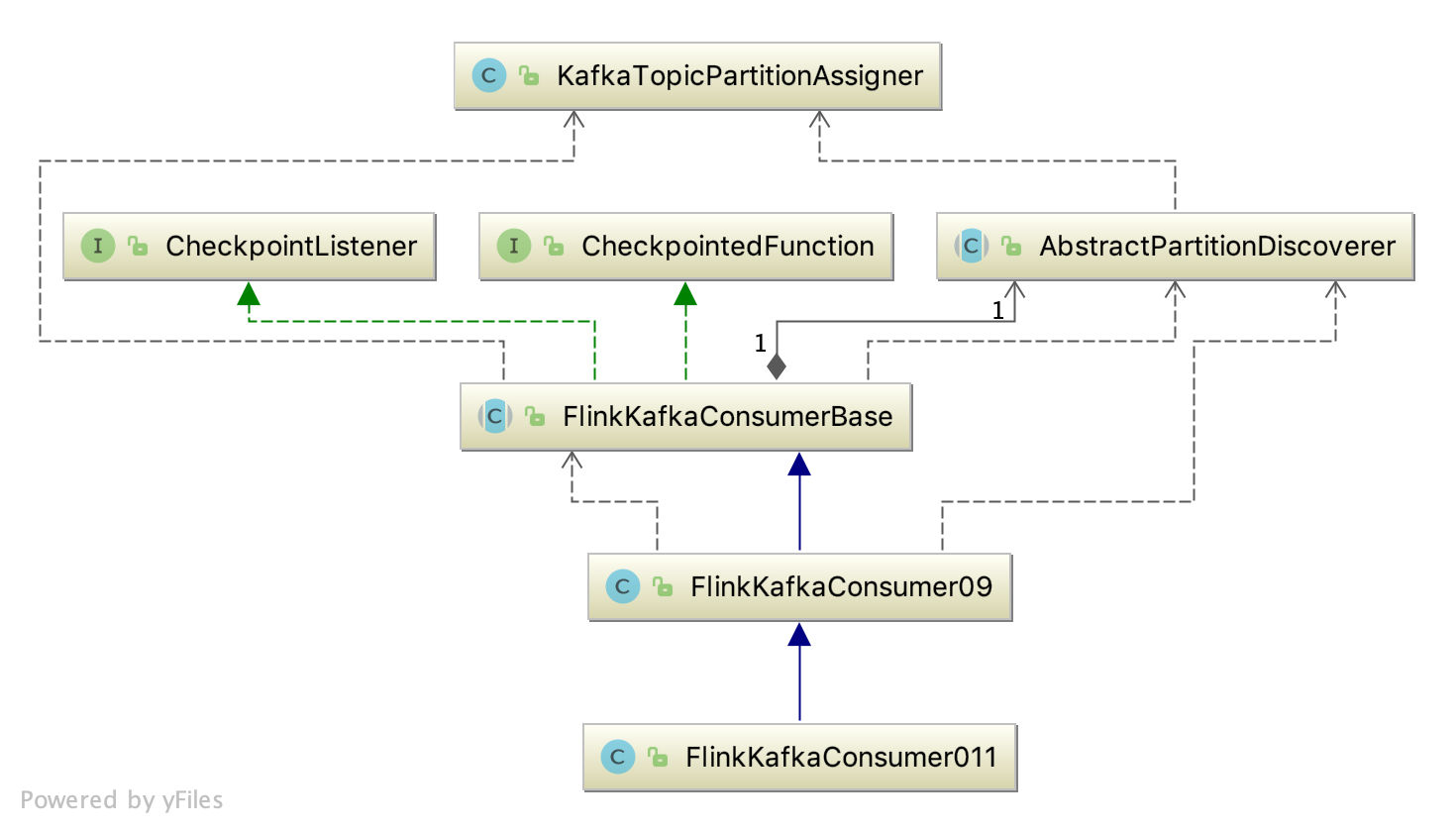
笔者生产环境使用的 FlinkKafkaConsumer011,FlinkKafkaConsumer011 继承 FlinkKafkaConsumer09,FlinkKafkaConsumer09 继承 FlinkKafkaConsumerBase。将参数 KEY_PARTITIONDISCOVERY_INTERVAL_MILLIS 传递给 FlinkKafkaConsumer011 时,在 FlinkKafkaConsumer09 的构造器中会调用 getLong(checkNotNull(props, “props”), KEY_PARTITION_DISCOVERY_INTERVALMILLIS, PARTITION_DISCOVERY_DISABLED) 解析该参数,并最终赋值给 FlinkKafkaConsumerBase 的 discoveryIntervalMillis 属性。后续相关源码如下所示:
1 | // FlinkKafkaConsumerBase 的 run 方法 |
discoveryLoopThread 线程中每间隔 discoveryIntervalMillis 时间会调用 partition 发现器获取该 subtask 应该消费且新发现的 partition,在 open 方法初始化时,同样也调用 partitionDiscoverer.discoverPartitions() 方法来获取新发现的 partition,partition 发现器的 discoverPartitions 方法第一次调用时,会返回该 subtask 所有的 partition,后续调用只会返回新发现的且应该被当前 subtask 消费的 partition。discoverPartitions 方法源码如下:
1 | public List<KafkaTopicPartition> discoverPartitions() throws WakeupException, ClosedException { |
上述代码中依赖 Set 类型的 discoveredPartitions 来判断 partition 是否是新的 partition,刚开始 discoveredPartitions 是一个空的 Set,所以任务初始化第一次调用发现器的 discoverPartitions 方法时,会把所有属于当前 subtask 的 partition 都返回,来保证所有属于当前 subtask 的 partition 都能被消费到。之后任务运行过程中,若创建了新的 partition,则新 partition 对应的那一个 subtask 会自动发现并从 earliest 位置开始消费,新创建的 partition 对其他 subtask 并不会产生影响。


