Spark 中的数据倾斜问题主要指 shuffle 过程中由于不同的 key 对应的数据量不同导致的不同 task 所处理的数据量不同的问题。
表现
- Spark 作业的大部分 task 都执行迅速,只有有限的几个 task 执行的非常慢,此时可能出现了数据倾斜,作业可以运行,但是运行的非常慢。
- 原本能够正常执行的 Spark 作业,突然出现 OOM[内存溢出] 异常
定位数据倾斜
在 Spark 中,同一个 Stage 的不同 Partition 可以并行处理,而具有依赖关系的不同 Stage 之间是串行处理的。假设某个 Spark Job 分为 Stage 0 和 Stage 1 两个 Stage,且 Stage 1 依赖于 Stage 0,那 Stage 0 完全处理结束之前不会处理 Stage 1。而 Stage 0 可能包含 N 个Task,这 N 个Task可以并行进行。如果其中 N-1 个 Task 都在10秒内完成,而另外一个 Task 却耗时1分钟,那该 Stage 的总时间至少为1分钟。换句话说,一个 Stage 所耗费的时间,主要由最慢的那个 Task 决定。
由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同Task之间耗时的差异主要由该 Task 所处理的数据量决定。
Stage 的数据来源主要分为如下两类
- 从数据源直接读取。如读取 HDFS,Kafka
- 读取上一个 Stage 的 Shuffle 数据
常用并且可能会触发 shuffle 操作的算子有:distinct,groupByKey,reduceByKey,aggregateByKey,join 等。出现数据倾斜,很有可能就是使用了这些算子中的某一个导致的。
如果我们是 yarn-client 模式提交,我们可以在本地直接查看 log,在 log 中定位到当前运行到了哪个 stage
如果用的 yarn-cluster 模式提交的话,我们可以通过 spark web UI 来查看当前运行到了哪个 stage。
无论用的哪种模式我们都可以在 Spark web UI 上面查看到当前这个 stage 的各个 task 的数据量和运行时间,从而能够进一步确定是不是 task 的数据分配不均导致的数据倾斜。
当确定了发生数据倾斜的 stage 后,我们可以找出会触发 shuffle 的算子,推算出发生倾斜的那个 stage 对应代码。触发 shuffle 操作的除了上面提到的那些算子外,还要注意使用 spark sql 的某些 sql 语句,比如 group by 等。
解决策略
数据源的数据倾斜
尽量避免数据源的数据倾斜,以 Spark Stream 通过 DirectStream 方式读取 Kafka 数据为例。由于Kafka 的每一个 Partition 对应 Spark 的一个 Task(Partition),所以 Kafka 内相关 Topic 的各 Partition 之间数据是否平衡,直接决定 Spark 处理该数据时是否会产生数据倾斜。
Kafka 某一 Topic 内消息在不同 Partition 之间的分布,主要由 Producer 端所使用的 Partition 实现类决定。如果使用随机 Partitioner,则每条消息会随机发送到一个 Partition 中,从而从概率上来讲,各 Partition 间的数据会达到平衡。此时源直接读取 Kafka 数据的 Stage 不会产生数据倾斜。
但很多时候,业务场景可能会要求将具备同一特征的数据顺序消费,此时就需要将具有相同特征的数据放于同一个Partition中。一个典型的场景是,需要将同一个用户相关的 PV 信息置于同一个 Partition 中。此时,如果产生了数据倾斜,则需要通过其它方式处理。
过滤异常数据
如果导致数据倾斜的 key 是异常数据,那么简单的过滤掉就可以了。
首先要对 key 进行分析,判断是哪些 key 造成数据倾斜。然后对这些 key 对应的记录进行分析:
- 空值或者异常值之类的,大多是这个原因引起
- 无效数据,大量重复的测试数据或是对结果影响不大的有效数据
- 有效数据,业务导致的正常数据分布
解决方案
对于第 1,2 种情况,直接对数据进行过滤即可。第3种情况则需要特殊的处理,具体我们下面详细介绍
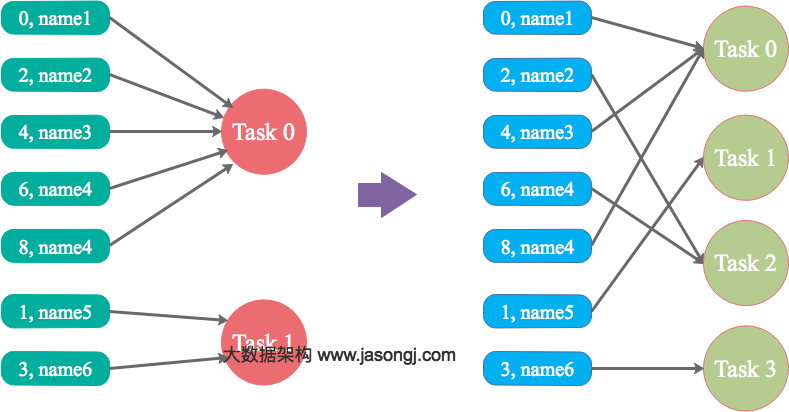
调整并行度分散同一个 Task 的不同 Key
Spark 在做 Shuffle 时,默认使用 HashPartitioner 对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,从而造成数据倾斜。
如果调整 Shuffle 时的并行度,使得原本被分配到同一 Task 的不同 Key 发配到不同 Task 上处理,则可降低原 Task 所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。
优势
实现简单,可在需要 Shuffle 的操作算子上直接设置并行度或者使用spark.default.parallelism设置。如果是Spark SQL,还可通过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。
劣势
适用场景少,只能将分配到同一Task 的不同 Key 分散开,但对于同一 Key 倾斜严重的情况该方法并不适用。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
方案实践经验
该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用嘴简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
自定义 Partitioner
适用场景
大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
解决方案
使用自定义的 Partitioner 实现类代替默认的 HashPartitioner,尽量将所有不同的 Key 均匀分配到不同的Task中。
优势
不影响原有的并行度设计。如果改变并行度,后续 Stage 的并行度也会默认改变,可能会影响后续 Stage。
劣势
适用场景有限,只能将不同 Key 分散开,对于同一 Key 对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的 Partitioner,不够灵活。
两阶段聚合(局部聚合+全局聚合)
在 Spark 中使用 groupByKey 和 reduceByKey 这两个算子会进行 shuffle 操作。这时候如果 map 端的文件每个 key 的数据量偏差很大,很容易会造成数据倾斜。
我们可以先对需要操作的数据中的 key 拼接上随机数进行打散分组,这样原来是一个 key 的数据可能会被分到多个 key 上,然后进行一次聚合,聚合完之后将原来拼在 key 上的随机数去掉,再进行聚合,这样对数据倾斜会有比较好的效果。
这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个 key 都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案缺点:仅仅适用于聚合类的 shuffle 操作,适用范围相对较窄。如果是 join 类的 shuffle 操作,还得用其他的解决方案。
将 reduce join 转换为 map join
通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。
两个 RDD 在进行 join 时会有 shuffle 操作,如果每个 key 对应的数据分布不均匀也会有数据倾斜发生。
这种情况下,如果两个 RDD 中某个 RDD 的数据量不大,可以将该 RDD 的数据提取出来,然后做成广播变量,将数据量大的那个 RDD 做 map 算子操作,然后在 map 算子内和广播变量进行 join,这样可以避免了 join 过程中的 shuffle,也就避免了 shuffle 过程中可能会出现的数据倾斜现象。
适用场景
参与 Join 的一边数据集足够小,可被加载进 Driver 并通过 Broadcast 方法广播到各个 Executor 中。
解决方案
在 Java/Scala 代码中将小数据集数据拉取到 Driver,然后通过 broadcast 方案将小数据集的数据广播到各 Executor。或者在使用 SQL 前,将 broadcast 的阈值调整得足够多,从而使用 broadcast 生效。进而将 Reduce 侧 Join 替换为 Map 侧 Join。

案例
优势
避免了 Shuffle,彻底消除了数据倾斜产生的条件,可极大提升性能。
劣势
要求参与 Join 的一侧数据集足够小,并且主要适用于 Join 的场景,不适合聚合的场景,适用条件有限。
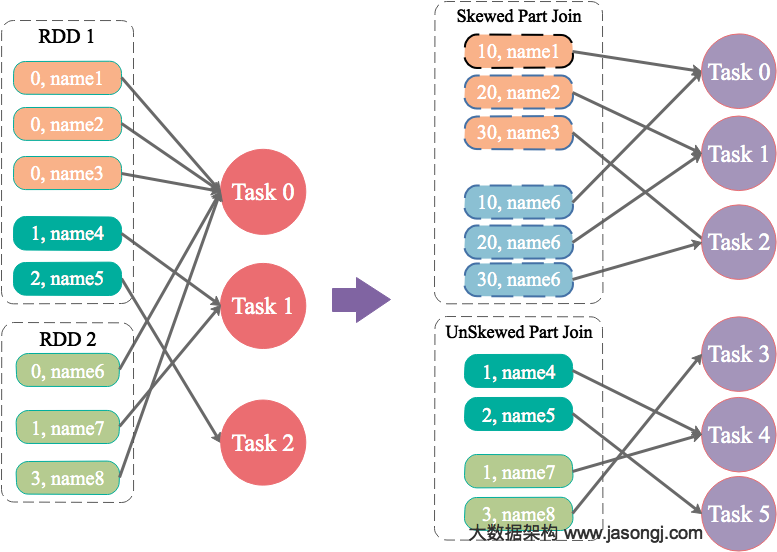
为 skew 的 key 增加随机前/后缀,拆分 join 再 union
为数据量特别大的 Key 增加随机前/后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一则的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常 Join。
适用场景
两张表都比较大,无法使用Map则Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
解决方案
将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join并去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
优势
相对于 Map 则Join,更能适应大数据集的 Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
劣势
如果倾斜 Key 非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜Key与非倾斜Key分开处理,需要扫描数据集两遍,增加了开销。
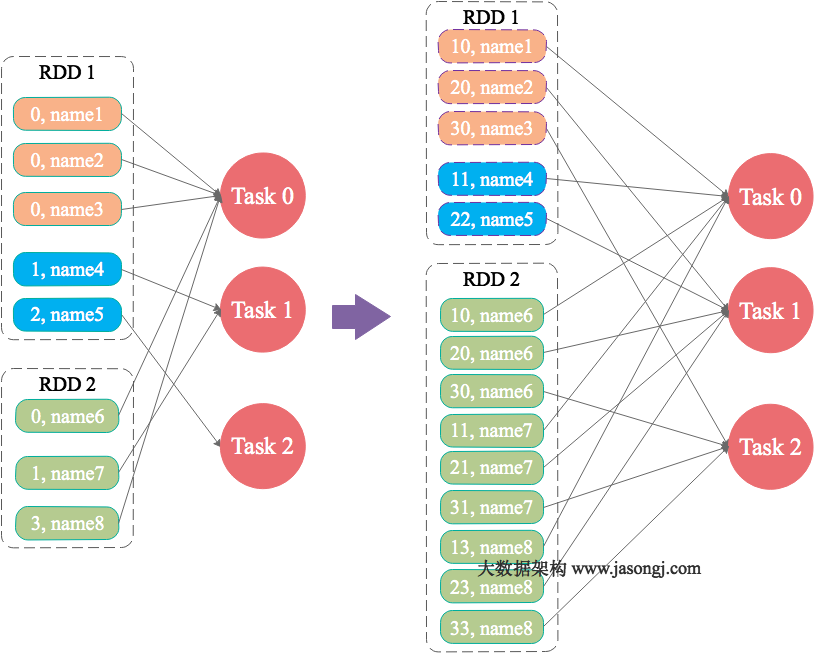
大表 key 加盐,小表扩大 N 倍 join
原理
如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍)。
适用场景
一个数据集存在的倾斜Key比较多,另外一个数据集数据分布比较均匀。
优势
对大部分场景都适用,效果不错。
劣势
需要将一个数据集整体扩大N倍,会增加资源消耗。


